
Weighted K-Means Clustering example - artificial countries
Introduction
One of fields where WKMC algorithm can be applied is demographics. Imagine a situation, in which you would like to see how people group or would group if all administation divisions or historical conflicts disappeared or ethnical, national or tribal identity would not matter? How would then people go about creating communities?
In this post, we will use the WKMC algorithm to find out how people would group only based on their present geographical distribution. For this reason we will look at two parameters:
- Geographical coordinates,
- Population density at specific location.
As this is a curiosity-driven simulation, it is a great simplification that possesses purely hypothetical character. The simulation does not take into account conditions such as natural resources or terrain barriers that would prevent people from settling. Antarctica is the only exception though. We exclude it, as it is a large part of the map, too large for the algorithm to ignore, yet almost completely unhabitable.
The dataset
We will use population density dataset available at NASA. The site offers four versions of the dataset, available in different resolution, which are good for experimentation.
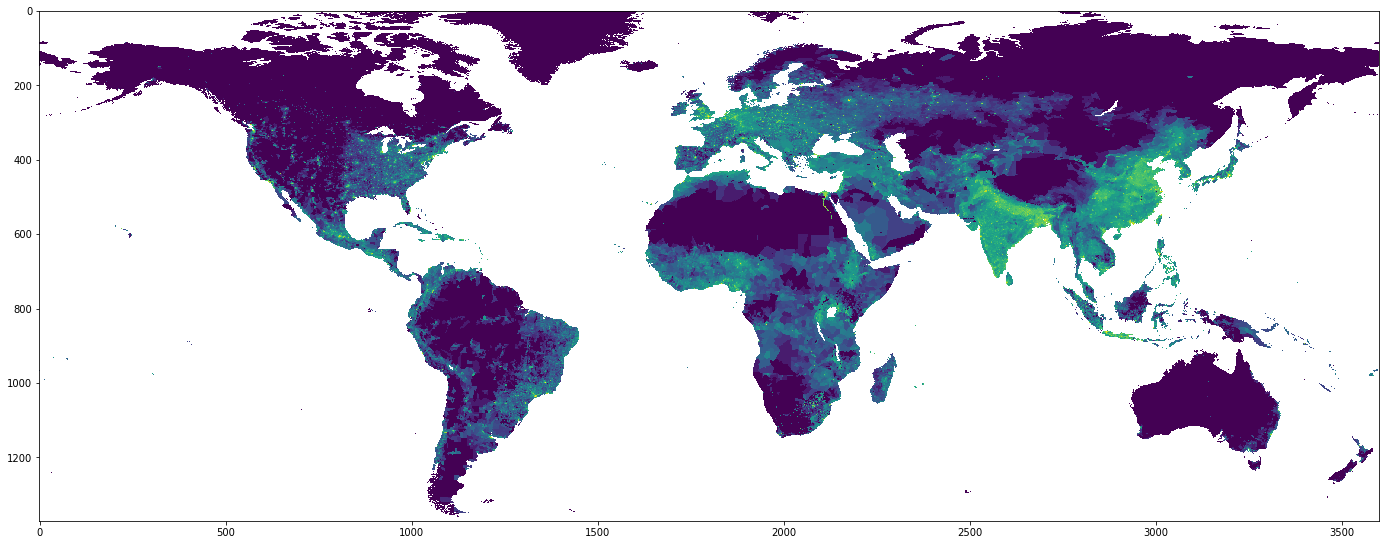
The dataset comes in four different resolution versions. Naturally, the highest resolution one gives the best results, although the computatin tie necessary may become an issue. To get the dataset, execute:
mkdir dataset
wget -O dataset/world.csv "https://neo.sci.gsfc.nasa.gov/servlet/RenderData?si=875430&cs=rgb&format=CSV&width=360&height=180"then:
1
2
3
4
5
6
7
8
import pandas as pd
df = pd.read_csv('./dataset/world.csv', header=-1)
df = df.replace(df.max().max(), 0)
df = df.loc[10:145, :]
df = df.reset_index()
df = df.drop(columns=['index'])
df.columns = range(df.shape[1])
For this dataset, the geographical longitude and latitude are simply expressed as integer numbers and treates as (x, y) indices of a matrix, and the map has cylindrical representation. At the same time, every element of this matrix represents population density of people living at a particular region.
The oceans are marked as 99999.0, which is unnatural and thus we put it to zero.
Later, we remove a “strip” of Arctic ocean (just to speed up the computation slightly) and Antarctica, as metioned earlier.
Then, we re-enumerate the indices for rows and columns to have them count from zero.
Feature engineering
Before we proceed, we need to transform our dataset a bit in order to fit in with the clustering problem. First of all, we need to change the representation of the dataset from a population density matrix to a list of longitude and latitude coordinate points, in order for the WKMC be able to calculate distance. However, we also need to keep the population density value, which both us and the machine can interpret as weight of each data point. In other words, large settlements such as big cities will have much stronger tendency to pull the nearest points into the clusters comparing to rural areas or deserts.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
latitude_idx = df.index.to_numpy()
longitude_idx = df.columns.to_numpy()
lat_max = len(latitude_idx)
lon_max = len(longitude_idx)
x0 = latitude_idx.repeat(lon_max)
x1 = np.tile(longitude_idx, lat_max)
x = df.to_numpy()
dd = pd.DataFrame({
'x0': x0,
'x1': x1,
'weight': x.flatten()
})
First, we extract the latitude and longitude from the dataframe object. Then, we repeat the latitude and latitude values, so that they form unique pairs ordered along some new index. We also dump all the weights and flatten them to a series, which we join into a new dataframe, so we can keep the refernce.
The world is round…
We know that nowadays people tend to put everything for a debate, but no… the Earth is still round. Here, we have a cylindrically represented map, which has an important consequence: the left and the right edge of the map are connected together. It is therefore vital to ensure that our algorithm will not treat two points residing close to the two edges as very separated.
Because the skearn API does not allow us to override the distance metrics easily, we have to parametrize the dataset differently:
1
2
3
dd['latitude'] = (x0 / x0.max() - 0.5) * 2.0
dd['longitude_sin'] = np.sin((x1 / x1.max()) * np.pi * 2.0)
dd['longitude_cos'] = np.cos((x1 / x1.max()) * np.pi * 2.0)
The longitude is the dimention that is cyclic, and if we scaled it to an interval of [0:2.0*np.pi], it would literally become the longitudonal angle.
The problem is that the difference between 1st and the 360th degree is 360 degrees, while the distance should be equal to one degree.
Therefore, we can decompose this dimension into two features, and use sine and cosine, respectively.
The latitude should not be cyclic here. However, if we look at the longitude related features we just defined, we can see that the maximum that can occur along there axes is 2. Therefore, in order to compensate for it when scaling of latitude, we need to ensure that the maximum distance along it is also 2.
Because our dataframe dd keeps all the references, we can simply add the new features into it, which we just did.
Solution
Now, our feature matrix X can be constructed by referecing all points through latitude and the sine/cosine projectins of the longitude.
At the same time, we take the population density to act as weights.
Before we do that, however, we remove all points whose weight is strickly zero.
As our plane’s surface is around 70% water, it can drastically reduce the computation needed.
1
2
3
4
5
6
7
8
9
10
11
12
N_CLUSTERS = 195
dd = dd[dd['weight'] != 0.0]
dd = dd.reset_index()
dd = dd.drop(columns=['index'])
X = dd[['latitude', 'longitude_sin', 'longitude_cos']].to_numpy()
weights = dd['weight'].to_numpy()
dd['cluster'] = KMeans(n_clusters=N_CLUSTERS).fit_predict(X,
sample_weight=weights)
The number 195 is not accidental. Currently, we have 195 regions recognized as countries. We can use this number as reference in our new world.
Having solved the WKMC problem, we need to “recombine” the solution to the old coordinates, which is fairly easy, given we have kept reference to the original indices.
1
2
3
4
5
XX = -1 * np.ones((lat_max, lon_max))
for i in range(len(dd)):
u, v = dd['x0'].iloc[0], dd['x1'].ilox[i]
cluster_id = dd['cluster'].iloc[i]
XX[u, v] = cluster_id
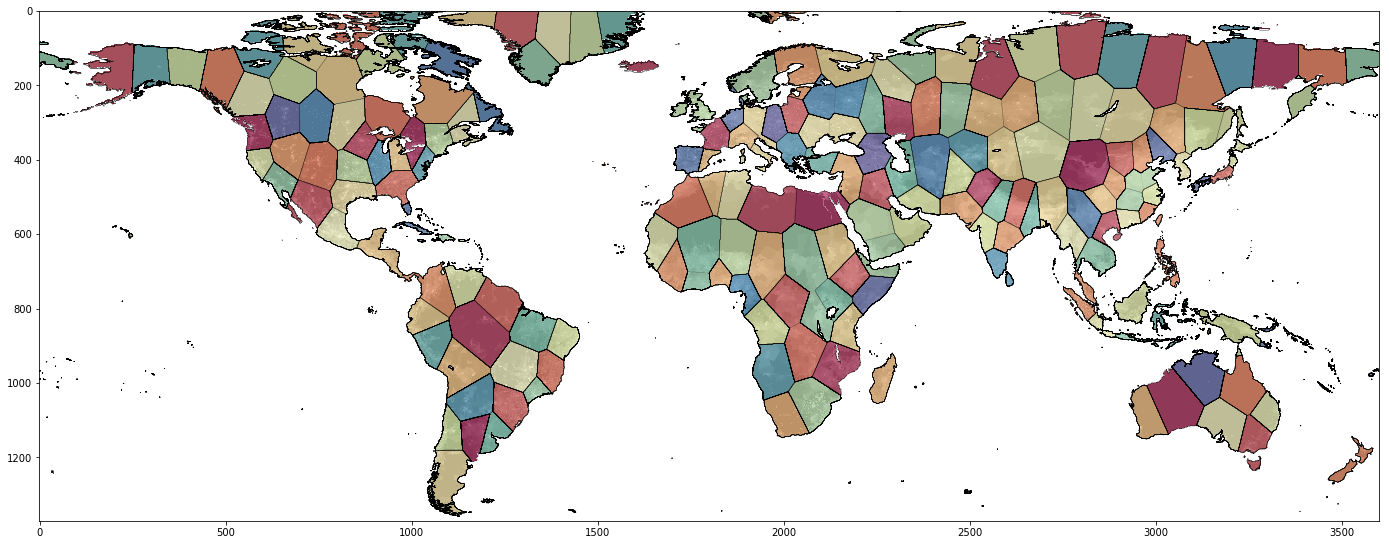
Now, let’s plot the results.
We will overlay the original population density map with the new “countries”.
(Note that the np.where function is only used here for enhancing of the plot.)
1
2
3
4
5
6
7
8
9
10
11
12
fig, ax = plt.subplots(1, 1, figsize=(24, 24))
ax.imshow(np.where(XX == -1, np.NaN, XX),
cmap='Spectral',
alpha=0.75)
ax.imshow(df.apply(lambda x: np.log(x)), alpha=0.25, cmap='gray')
ax.contour(longitude_idx, latitude_idx,
np.where(XX == -1, -10, XX),
levels=N_CLUSTERS,
linewidths=0.1,
alpha=0.5,
colors='k')
plt.show()
Discussion
We have finally clustered the population. It is useful to observe the consequences of WKMC algorithm’s assumptions.
First of all, as we have removed the points of zero weights, no clusters’ labels are assinged to those points. However, the larger the population density, the more concentrated the clusters became. This is especially visible in regions of India and China that are ones of the most densely populated regions in the world. Siberia and Northern parts of Canada, Greenland, Sahara and Australia form larger clusters.
Secondly, by scaling of the features (remember, all features are in range [-1, 1]), the clusters do not exhibit anisotropy in any of directions.
In other words, if e.g. the x-axis had 5 times the range, we would expect it’s influence to be much stronger and thus the cluster would be elongated vertically.
Finally, by ensuring the continuity in East-West axis, our clusters are not distorted by presence of the boundary conditions.
Conclusions
We have seen how K-Means Clustering algorithm can be put into use in our hypothetical world. However, the usage just demonstrated is actually very traditional, and can be applied in similar situations, giving especially good results when working on smaller maps. The algorithm helps to spot similarities that exist regardless of any administrative divisions.