
Why using SQL before using Pandas?
Introduction
Data analysis is one of the most essential steps in any data-related project. Regardless of the context (e.g. business, machine-learning, physics, etc.), there are many ways to get it right… or wrong. After all, decisions often depend on actual findings. and at the same time, nobody can tell you what to find before you have found it.
For these reasons, it is important to try to keep the process as smooth as possible. On one hand, we want to get into the essence quickly. On the other, we do not want to complicate the code. If cleaning the code takes longer than cleaning data, you know something is not right.
In this article, we focus on fetching data. More precisely, we show how to get the same results with both Python’s key analytics library, namely Pandas and SQL. Using an example dataset (see later), we describe some common patterns related to preparation and data analysis. Then we explain how to get the same results with either of them and discuss which one may be preferred. So, irrespectively if you know one way, but not the other, or you feel familiar with both, we invite you to read this article.
The example dataset
“NIPS Papers” from Kaggle will serve us an example dataset. We have purposely chosen this dataset for the following reasons:
- It is provided as an SQLite file, thus we can simulate a common scenario, where data is obtained from a relational database, e.g. a data warehouse.
- It contains more than one table, so we can also show how to combine the data, which is a frequently encountered problem.
- It is imperfect: there will be nulls, NaNs, and some other common issues… life ;)
- It is simple to understand, contains only two data tables (“authors” and “papers”), plus the third to establish a many-to-many relationship between them. Thanks to that, we can focus on methodology rather than the actual content.
- Finally, the dataset comes also as a CSV file.
You are welcome to explore it yourself. However, as we focus on the methodology, we limit to discuss the content to a bare minimum. Let’s dive in.
Fetching data
The way you pick the data depends on its format and the way it is stored. If the format is fixed, we get very little choice on how we pick it up. However, if the data sits in some database, we have more options.
The simplest and perhaps the most naive way is to fetch it table after table and store them locally as CSV files. This is not the best approach for two main reasons:
- The total data volume is unnecessarily larger. You have to deal with excess data that is not information (indices, auxiliary columns, etc.).
- Depending on the data, notebooks will contain substantial cleaning and processing code overhead, obscuring the actual analytics.
You don’t want any of these. However, if you have no clue about the data, fetching everything is the safest option.
Let’s take a look at what tables and columns the “NIPS” has.
table authors
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import pandas as pd
df_authors = pd.read_csv("data/authors.csv")
df_auhtors.info()
# returns
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 9784 entries, 0 to 9783
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 9784 non-null int64
1 name 9784 non-null object
dtypes: int64(1), object(1)
memory usage: 153.0+ KB
table papers
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
df_papers = pd.read_csv("data/papers.csv")
df_papers.info()
# returns
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7241 entries, 0 to 7240
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 7241 non-null int64
1 year 7241 non-null int64
2 title 7241 non-null object
3 event_type 2422 non-null object
4 pdf_name 7241 non-null object
5 abstract 7241 non-null object
6 paper_text 7241 non-null object
dtypes: int64(2), object(5)
memory usage: 396.1+ KB
table paper_authors
As mentioned earlier, this table links the former two,
using author_id and paper_id foreign keys.
In addition, it has its own primary key id.
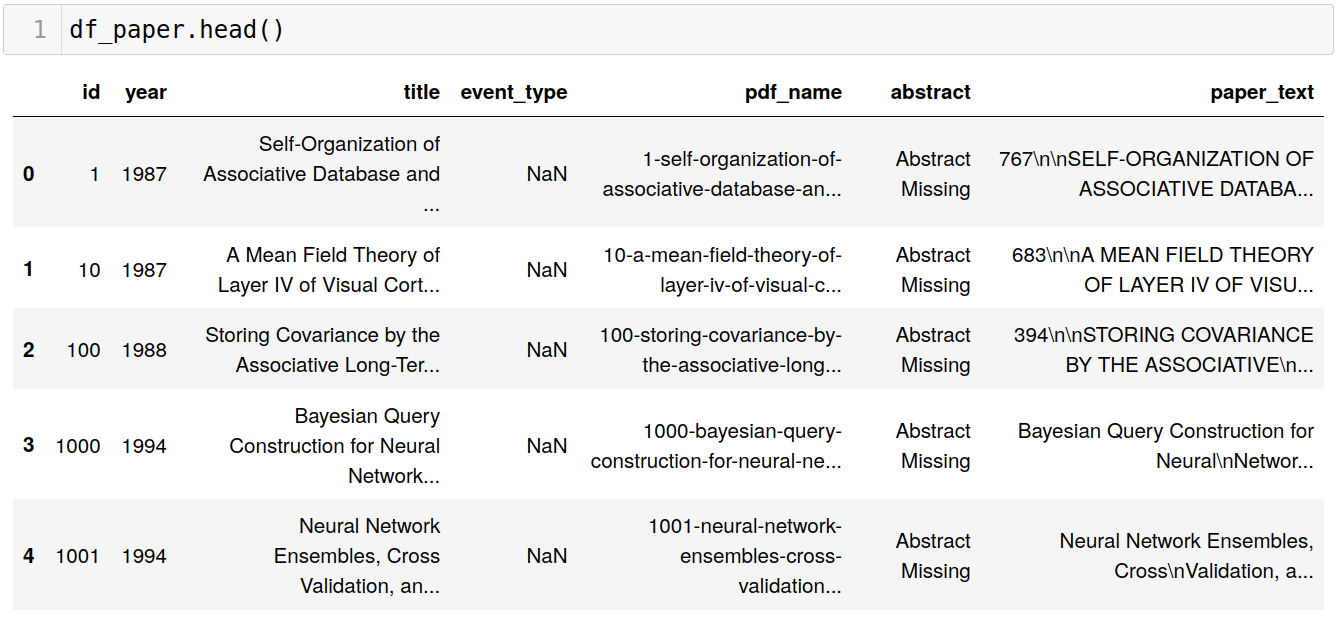
As we can see from the image (and also when digging into the analytics deeper),
the pdf_name column is more or less redundant, given the title column.
Furthermore, by calling df_papers["event_type"].unique(), we know
there are four distinct values for this column: 'Oral', 'Spotlight', 'Poster'
or NaN (which signifies a publication was indeed a paper).
Let’s say, we would like to filter away pdf_name together with any entry that
represents any publication that is other than a usual paper.
The code to do it in Pandas looks like this:
1
2
3
df = df_papers[~df_papers["event_type"] \
.isin(["Oral", "Spotlight", "Poster"])] \
[["year", "title", "abstract", "paper_text"]]
The line is composed of three parts.
First, we pass df_papers["event_type"].isin(...), which is a condition
giving us a binary mask,
then we pass it on to df_papers[...] essentially filtering the rows.
Finally, we attach a list of columns ["year", "title", "abstract", "paper_text"]
to what is left (again using [...]) thus indicating the columns we want to preserve.
Alternatively, we may also use .drop(columns=[...]) to indicate the unwanted columns.
A more elegant way to achieve the same result is to use Pandas’
.query method instead of using a binary mask.
1
2
3
df = df_papers \
.query("event_type not in ('Oral', 'Spotlight', 'Poster')") \
.drop(columns=["id", "event_type", "abstract"])
The code looks a bit cleaner, and a nice thing about .query is the fact, we can
use @-sign to refer to another object, for example
.query("column_a > @ass and column_b not in @bees").
On the flip side, this method is a bit slower, so you may want to stick to
the binary mask method when having to repeat it excessively.
Using SQL for getting data
Pandas gets the job done. However, we do have databases for a reason. They are optimized to search through tables efficiently and deliver data as needed.
Coming back to our problem, all we have achieved here is simple filtering of columns and rows. Let’s delegate the task to the database itself, and use Pandas to fetch the prepared table.
Pandas provides three functions that can help us: pd.read_sql_table, pd.read_sql_query
and pd.read_sql that can accept both a query or a table name.
For SQLite pd.read_sql_table is not supported.
This is not a problem as we are interested in querying the data at the database level anyway.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import sqlite3 # or sqlalchemy.create_engine for e.g. Postgres
con = sqlite3.connect(DB_FILEPATH)
query = """
select
year,
title,
abstract,
paper_text
from papers
where trim(event_type) != ''
"""
df_papers_sql = pd.read_sql(query, con=con)
Let’s break it down.
First, we need to connect to the database.
For SQLite, it is easy, as we are only providing a path to a database file.
For other databases, there are other libraries (e.g. psycopg2 for Postgres
or more generic: sqlalchemy).
The point is to create the database connection object that points Pandas
in the right direction and sorts the authentication.
Once it is settled, the only thing left is constructing the right SQL query.
SQL filters columns through the select statement.
Similarly, rows are filtered with the where clause.
Here we use the trim function to
strip the entires from spaces, leaving us everything, but an empty string
to pick up.
The reason we use trim is specific to the data content of this example,
but generally where is a place to put a condition.
With read_sql, the data is automatically DataFrame‘ed
with all the rows and columns prefiltered as described.
Nice, isn’t it?
Let’s move further…
Joining, merging, collecting, combining…
Oftentimes data is stored across several tables. In these cases, stitching a dataset becomes an additional step that precedes the analytics.
Here, the relationship is rather simple:
there is a many-to-many relationship between authors and papers,
and the two tables are linked through the third, namely papers_authors.
Let’s take a look at how Pandas handles the case.
For the sake of argument, let’s assume we want to find the most “productive”
authors in terms of papers published.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
df_authors \
.merge(
df_papers_authors.drop(columns=["id"]),
left_on="id",
right_on="author_id",
how="inner") \
.drop(columns=["id"]) \
.merge(
df_papers \
.query("event_type in ('Oral', 'Spotlight', 'Poster')") \
[["id", "year", "title", "abstract", "paper_text"]],
left_on="paper_id",
right_on="id",
how="left") \
.drop(columns=["id", "paper_id", "author_id"]) \
.sort_values(by=["name", "year"], ascending=True)
… for Python, this is just one line of code, but here we split it into several for clarity.
We start with the table authors and want to assign papers.
Pandas offers three functions for “combining” data.
pd.concat- concatenates tables by rows or columns. Similar to SQL’sunion.pd.join- joins two tables just like SQL’sjoin, but requires the index to be the actual DataFrame index.pd.merge- the same, but more flexible: can join using both indices and columns.
To “get” to papers, we first need to inner-join the papers_authors
table. However, both tables have an id column.
To avoid conflict (or automatic prefixing), we remove the papers_authors.id column
before joining.
Then, we join on authors.id == papers_authors.author_id, after which we also
drop id from the resulting table.
Having access to papers_id, we perform joining again.
This time, it is a left-join as we don’t want to eliminate “paperless” authors.
We also take the opportunity to filter df_papers as described earlier.
However, it is essential to keep papers.id or else Pandas will refuse
to join them.
Finally, we drop all indices: id, paper_id, author_id as they don’t
bring any information and sort the records for convenience.
Using SQL for combining
Now, the same effect using SQL.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
query = """
select
a.name,
p.year,
p.title,
p.abstract,
p.paper_text
from authors a
inner join paper_authors pa on pa.author_id = a.id
left join papers p on p.id = pa.paper_id
and p.event_type not in ('Oral', 'Spotlight', 'Poster')
order by name, year asc
"""
pd.read_sql(query, con=con)
Here, we build it “outwards” from line 8., subsequently joining the other
tables, with the second one being trimmed using line 11..
The rest is just ordering and filtering using a, p, pa as an alias.
The effect is the same, but with SQL, we avoid having to manage indices, which has nothing to do with analytics.
Data cleaning
Let’s take a look at the resulting dataset.

The newly created table contains missing values and encoding problems.
Here, we skip fixing the encoding as this problem is specific to the data content.
However, missing values are a very common issue.
Pandas offers, among others, .fillna(...) and .dropna(...),
and depending on the conventions, we may fill NaNs with different values.
Using SQL for data cleaning
Databases also have their way to deal with the issue.
Here, the equivalents to fillna and dropna
are coalesce and is not null, respectively.
Using coalesce, our query cures the dataset, injecting any value
in case it is missing.
1
2
3
4
5
6
7
8
9
10
11
12
13
"""
select
a.name,
coalesce(p.year, 0) as year,
coalesce(p.title, 'untitled') as title,
coalesce(p.abstract, 'Abstract Missing') as abstract,
coalesce(p.paper_text, '') as text,
from authors a
join paper_authors pa on pa.author_id = a.id
left join papers p on p.id = pa.paper_id
and p.event_type not in ('Oral', 'Spotlight', 'Poster')
order by name, year asc
"""
Aggregations
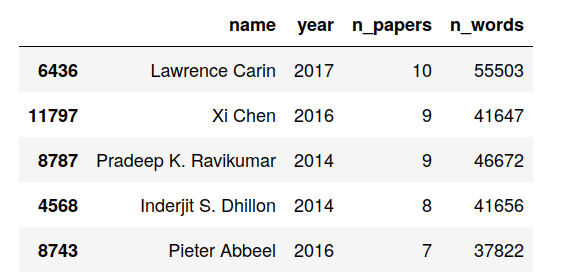
Our dataset is prepared, “healed” and fetched using SQL. Now, let’s take it we would like to rank the authors based on the number of papers they write each year. In addition, we would like to calculate the total word count that every author “produced” every year.
Again, this is another standard data transformation problem. Let’s examine how Pandas handles it. The starting point is the joint and cleaned table.
1
2
3
4
5
6
7
8
9
df["paper_length"] = df["paper_text"].str.count()
df[["name", "year", "title", "paper_length"]] \
.groupby(by=["name", "year"]) \
.aggregate({"title": "count", "paper_length": "sum"}) \
.reset_index() \
.rename(columns={"title": "n_papers", "paper_length": "n_words"}) \
.query("n_words > 0") \
.sort_values(by=["n_papers"], ascending=False)
We calculate articles’ length by counting spaces.
Although it is naive to believe that every word in a paper is separated by exactly
one space, it does give us some estimation.
Line 1. does that via .str attribute, introducing a new column at the same time.
Later on, we formulate a new table by applying a sequence of operations:
- We narrow down the table only to the columns of interest.
- We aggregate the table using both
nameandyearcolumns. - As we apply different aggregation functions to the two remaining columns,
we use the
.aggregatemethod that accepts a dictionary with instructions. - The aggregation results in having a double-index. Line
6.restoresnameandyearto columns. - The remaining columns’ names stay the same, but no longer reflect the meaning
for the numbers. We change that in line
7.. - For formerly missing values, it is safe to assume they have a word count equal to zero.
To build the ranking, we eliminate them using
.query. - Finally, we sort the table for convenience.
The aggregated table is presented in figure 3.
Using SQL to aggregate
Now, once again, let’s achieve the same result using SQL.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
"""
select
d.name,
d.year,
count(title) as n_papers,
sum(paper_length) as n_words
from (
select
a.name,
coalesce(p.year, 0) as year,
coalesce(p.title, 'untitled') as title,
length(coalesce(p.paper_text, ''))
- length(replace(coalesce(p.paper_text, ''), ' ', '')
as paper_length
from authors a
join papers_authors pa on pa.author_id = a.id
left join papers p on p.id = pa.paper_id
and p.event_type not in ('Oral', 'Spotlight', 'Poster')
) as d
group by name, year
having n_words > 0
order by n_papers desc
"""
This query may appear more hassle than the Pandas code, but it isn’t. We combine all our work plus the aggregation in a single step. Thanks to the subquery and functions, it is possible to arrange so that in our particular example, we may get the result, before we even start the analysis.
The query contains a subquery (lines 8.-18.), where
apart from removing abstract and introducing paper_length columns,
almost everything stays the same.
SQLite does not have an equivalent to str.count(), so we work around it
counting differences between spaces and all other words using length
and replace.
Later, in line 19., we assign d to be an alias for the
subquery table for reference.
Next, the groupby statement in combination with count and sum
is what we did using Pandas’ .aggregate method.
Here, we also apply the condition from line 21. using having.
The having statement works similarly to where except that it operates
“inside” the aggregation as opposed to where that is applied to
a table that is formulated to remove some of its records.
Again, the resulting tables are exactly the same.
Conclusion
Pandas and SQL may look similar, but their nature is very different. Python is an object-oriented language and Pandas stores data as table-like objects. In addition, it offers a wide variety of methods to transform them in any way possible, which makes it an excellent tool for data analysis.
On the opposite side, Pandas’ methods to formulate a dataset are just a different “incarnation” to what SQL is all about. SQL is a declarative language that is naturally tailored to fetch, transform and prepare a dataset. If data resides in a relational database, letting a database engine perform these steps is a better choice. Not only are these engines optimized to do that, but also letting a database prepare a clean and convenient dataset facilitates the analysis process.
The disadvantage of SQL is the fact it may be harder to read and to figure out data to throw away and what to keep, before creating a dataset. Pandas, running on Python, lets us assign fractions of the dataset to variables, inspect them, and then make further decisions.
Still, these temporary variables often creep to clutter the workspace… Therefore, unless you are in doubt, there are strong reasons to use SQL.
And how do you analyze your data? ;)